Getting started with OSVVM using Riviera-PRO.
Introduction
OSVVM is an intelligent testbench methodology that allows mixing of "Intelligent Coverage" with directed, algorithmic, file based, and constrained random approaches. OSVVM is an integrated environment designated for verification of VHDL. OSVVM stands for "Open Source VHDL Verification Methodology". OSVVM is a set of VHDL packages, initially developed by Aldec and Synthworks. OSVVM helps you adopt modern constrained random verification techniques using VHDL. With OSVVM, one can add advanced verification methodologies to their current testbenches without having to learn a new language or throw out the existing testbench model. This tutorial provides instructions for using the basic features of OSVVM for VHDL. OSVVM supports the same features as those based on other verification methodologies. That includes Transaction Level Modeling, Constraint ranbdom test generation, Functional Coverage, Message filtering ,Scoreboards and FIFOs, Error reporting,etc.
Why OSVVM?
Verification capabilities has been a large matter in all sort of designs. It is always hard to verify and debug the design than write the design code. Like System Verilog, writing directly in VHDL is error prone. OSVVM provides a methodology and library that simplifies the entire verification efforts for VHDL users. OSVVM demonstrates that a designer can have capability, simplicity and conciseness all from one language and a methodology.
Getting Started
First step to get started with OSVVM in Riviera-PRO is to make sure that you are using VHDL 2008 or beyond. For users using simulation tools other than Riviera-PRO might have to download OSVVM specifically from OSVVM website.
The key concepts which needs to be understood are following packages.They are always added in any OSVVM design as that represents the necessary OSVVM library packages:
library osvvm; use osvvm.RandomPkg.all; use osvvm.CoveragePkg.all;
Library Information:
RandomPkg
RandomPkg implements its randomization capability using a protected type, named RandomPType. Using a protected type allows the seed to be stored internal to the protected type, which in turn allows randomization to be done using functions. To use RandomPkg, first you must reference the OSVVM library and RandomPkg as shown below:
library osvvm; use osvvm.RandomPkg.all;
To do randomization, a process must declare its own local randomization variable. Each process doing randomization needs its own randomization variable with a unique seed value. One easy way to do this is to name the process and use RV'instance_name as a parameter to Initseed (For ex. RV.InitSeed(RV'instance_name);). Randomization is done with one of the overloaded functions such as RandInt (For ex. RandInt := RV.RandInt(0,255);).
CoveragePkg
CoveragePkg is released under the Perl Artistic Open Source License. It is free. You can download it from http://www.synthworks.com/downloads. It gets updated from time to time. Currently there are numerous planned revisions. CoveragePkg helps writing the Functional Coverage. Actually, Functional Coverage can be written using any code. CoveragePkg and language syntax are solely intended to simplify this effort. The basic steps to model Functional Coverage are declaring the Coverage object, create the coverage model, accumulate coverage, interact with the coverage data structure, and report the coverage. Coverage is modeled using a data structure stored inside of a coverage object. The coverage object is created by declaring a shared variable of type CovPType, such as one below:
architecture Test of tb is shared variable CovBin1 : CovPType;
Constrained Random Verification
Constrained Random Verification (sometimes known as Testbench Automation) has become popular over recent years for complex verification environments. The basic idea of constrained random verification is to use randomization as the basis of your approach to verification. Traditional testing uses so-called "directed" tests - that is the person writing the test has to decide exactly what stimulus to apply. Constrained random verification uses randomized inputs. This has a number of benefits:
If you simulate longer, you generate more test vectors.
You may find bugs due to unexpected combinations of inputs, or extreme input values. With directed testing, it is all too easy just to test what you expect to happen, rather than trying to test what you don't expect to happen.
Once you have developed an automated test, it can still be used for directed testing.
The main disadvantage of constrained random testing is that you need to have a self-checking testbench. The advantage is that a self-checking testbench is a good approach to verifying complex systems, but that requires that you have a reference model of your design-under-test(DUT). Considering all the explanations above, there still remains a question. What do we mean by the word "Constrained"? Randomization is all about randomizing the test-vectors for the DUT. Hence, having said that, it becomes difficult to know what has not been tested. To avoid that and to cover each and every test-points, we randomize test-vectors with certain constraints also known as Functional Coverage. Functional Coverage measures something that relates back to particular specification points to tell you whether that specification point has been covered. Note that this is not same as Code Coverage, which merely tells you if every line of code has been executed- but nothing about functionality. Even if every line of your code has been executed, your DUT may not be correct! OSVVM provides a way of collecting the values of nodes in your verification environment to help you decide when verification is complete.
Creating Random Values
In order to generate random values, first thing that we need to do is to include the appropriate packages. E.g.
library osvvm; use osvvm.RandomPkg.all; use osvvm.CoveragePkg.all; Next, we declare variables of the appropriate types. variable a1 : RandomPType; variable b1 : RandomPType;
Next, we create random values:
A <= a1.Randslv(0,255,8); B <= b1.Randslv(0,255,8);
Above lines shows how to create a random logic values of 8-bit wide with the full range of values from 0 to 255.
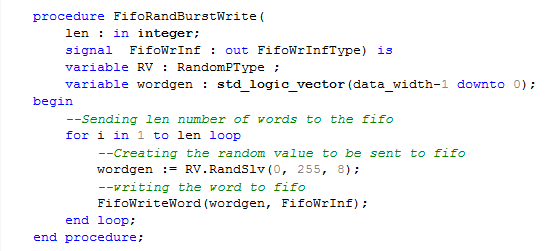
Figure 1. Code explanation
Creating Constraints and Distributions
The example above generated values over the full range. Although we might want to constrain the random item to particular ranges or values. The RandomPType allows us to specify exactly which values we want to get generated and their distribution.
abc <= Rndabc.Randslv(0,31,4); def <= Rnddef.Randslv((0,1,2,3,5,7,9,11,17,23,29,31),4);
First example shows the basic randomization over the full range of 0 to 31. Second example shows on the left hand side bracket already provided constraints and right hand side shows the width of 4 bits. Thus, there are many other options through which one can manipulate the randomization, constraining and Distributions in VHDL testbench.
Functional Coverage
Functional Coverage is a code that observes execution of a test plan. As such, it is code you write to track whether important values, sets of values, or sequences of values that correspond to design or interface requirements, features or boundary conditions have been exercised. Without Functional Coverage, you do not know what specific points your random testing has covered and more importantly, you do not know which points are yet not covered. In order to generate Functional Coverage, we measure the Coverpoint. The coverpoint has features which lets us collate data values into bins. Functional Coverage is obtained basically into 3 stages. I) setup, ii) sample and iii) report coverage. Coverpoints sample the integer values. In the sample process, the coverage is sampled. Finally, the Coverreport process writes out the measured coverage data when the simulation stops.
Creating Workspace and Design
In Riviera-PRO, individual designs along with their resources can be grouped together as a workspace. The workspace allows adding and working with several designs simultaneously.
Go to File | New and click Workspace. The new Workspace wizard starts.
Type the workspace name and select the location where you want to create the project.
Click OK button when you are done.(See below figure)
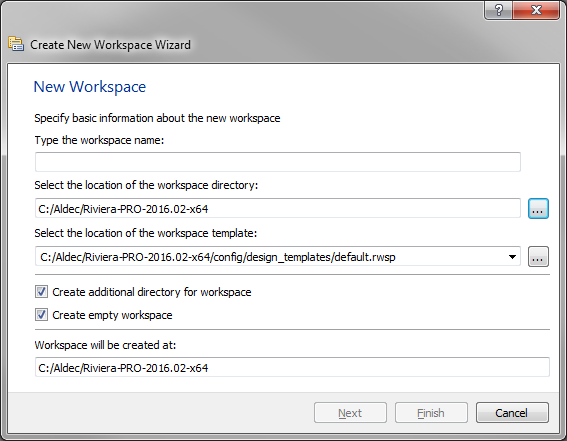
Figure 2. Creating new workspace
New Workspace will be created. Now right click on the workspace option and go to Add | New Design. Following window will pop up.
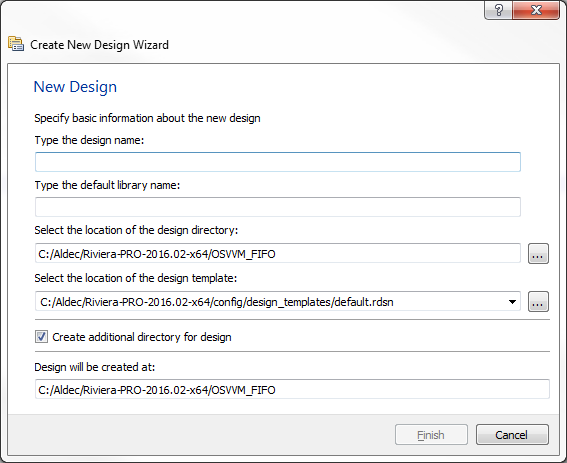
Figure 3. Creating new Design
Click Finish button when you are done.
The Design Manager now shows a Workspace name and new Design attached with it.
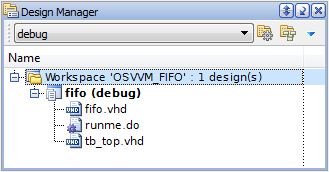
Figure 4. Design Manager Window
Creating/Adding Files to Design
To Create a new file or an existing file or to create a directory, right click anywhere into the Design Manager and Click Add | New File.
You can also use File | New menu to open new files and save it to design directory(Figure Below)
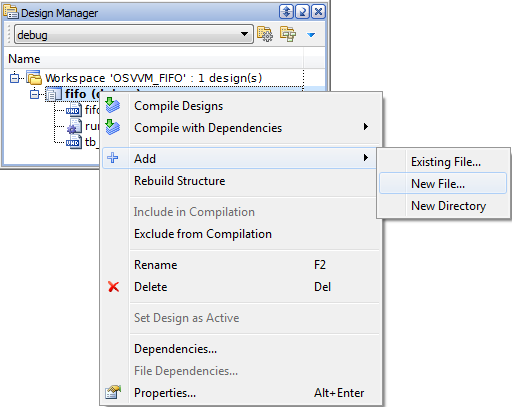
Figure 5. Creating/Adding files to Design
Creating HDL Source Code
If you want to create VHDL/Verilog/System C source files, double click the Add | New File option. However, here we have provided the OSVVM FIFO example implementation and hence we already have the file. So we have chosen Add | Existing File and attached the files that were required for implementation.
Compilation
Compilation is a process of analysis of a source file. Analyzed design units contained within the file are placed into the working library in a format understandable to the simulator.
Compiling Files
If you want to compile a single file, go to the Files in the Design Manager , right click the file and choose compile from the shortcut menu.
If you choose Compile All by right clicking the Design tab for a given design, the compiler automatically reorders the source files to ensure proper sequence in which design units are compiled.
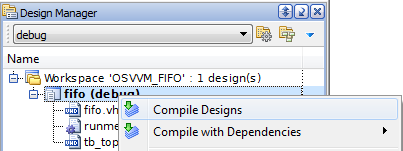
Figure 6. Compiling files using Design Manager
Initializing Simulation
Once all needed design units have been successfully compiled, you can initialize simulation. Before you initialize the simulation, make sure that:
You have selected the top-level design unit.
If you run the simulation without any top-level unit elected, simulator will prompt you with a dialog box to select one.
To begin simulation process, you must choose Initialize Simulation from the Simulation window. The command launches elaboration and initialization of the simulation model. During elaboration, the simulator loads design units and builds the simulation model in the computer memory. During the initialization, all objects in the model acquire their initial values and all concurrent processes are executed once until their suspension.
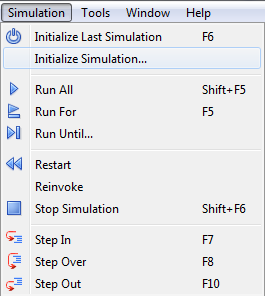
Figure 7. Simulation Window
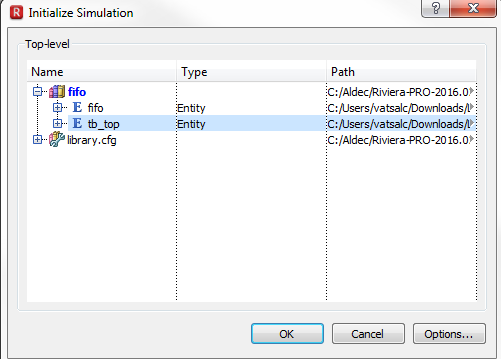
Figure 8. Initializing Simulation
Set your Testbench as your top-level hierarchy. Once you choose that, the Hierarchy Window will pop up. (Below Image)
Figure 9. Hierarchy Window
Once you get that, right click on your testbench module and choose Add to | Waveforms option. The waveform window will open up.
You can run the simulation by choosing the run option. By clicking that, the simulation will start running.
Run All/Run For/Run Until Simulation
To run the simulation for a certain amount of time in the simulation , choose the Run For option from the simulation menu.
To finish the simulation session, choose Stop Simulation from the Simulation menu.
You can restart the simulation, select Restart from the Simulation menu.
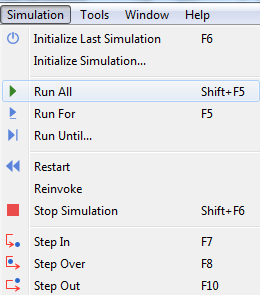
Figure 10. Run For/Run All/Run Until Simulation
Waveform Viewer
After following all the steps above, you might see the results into a waveform file as per below.
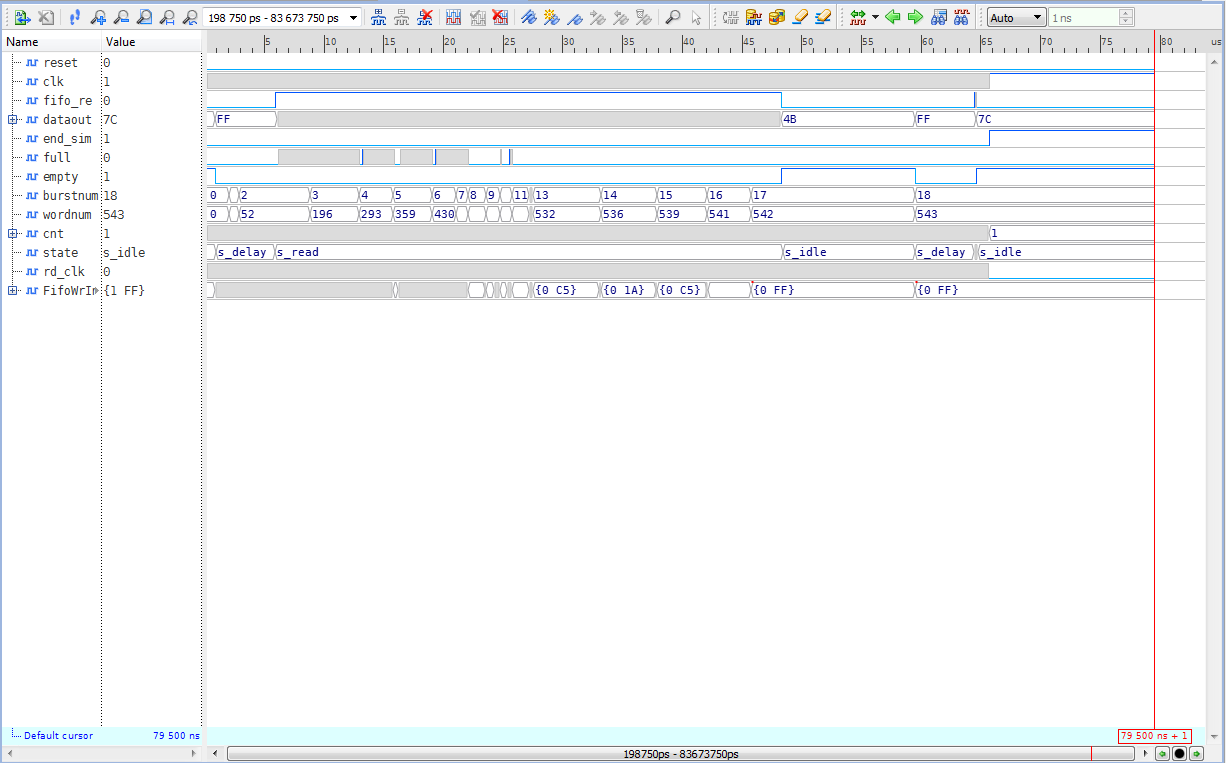
Figure 11. Waveform Viewer
To save a waveform file or to manipulate with the current waveform settings, you can go and select the Waveform menu option.
References
[1] Open Source VHDL Verification Methodology (http://osvvm.org/)
[2] Github (https://github.com/OSVVM/OSVVM)
Disclaimer:
Many of the text in this application note were extracted from the referenced sources regarding the open-source tools they provide. The intention of this application note is to consolidate and organize the data and present a simplified tool flow for the benefit of Aldec users.
Corporate Headquarters
2260 Corporate Circle
Henderson, NV 89074 USA
Tel: +1 702 990 4400
Fax: +1 702 990 4414
https://www.aldec.com
©2026 Aldec, Inc.
